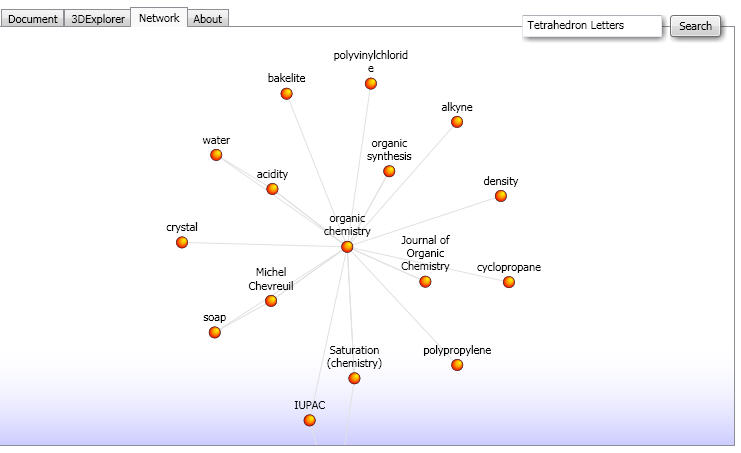
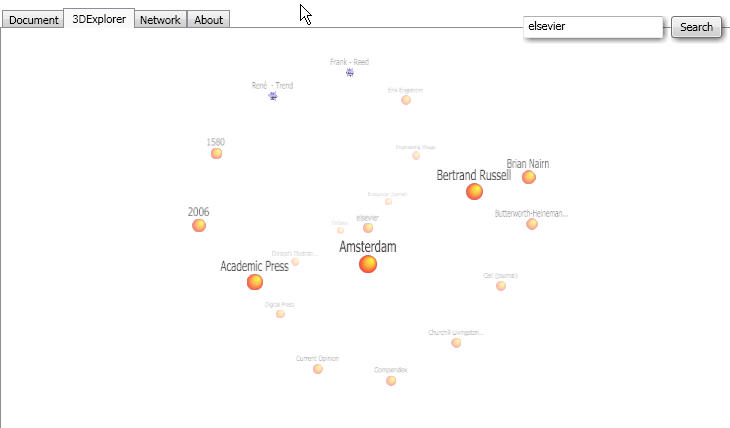
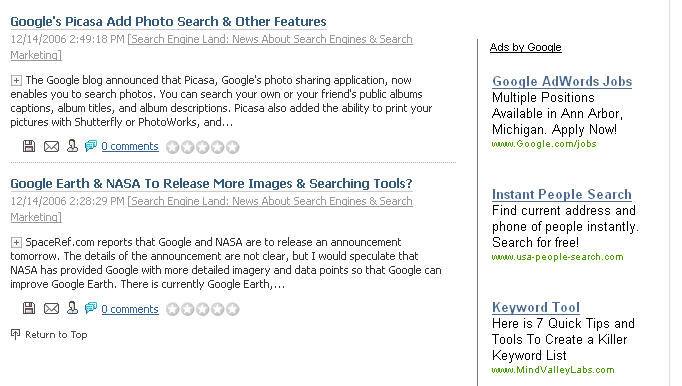
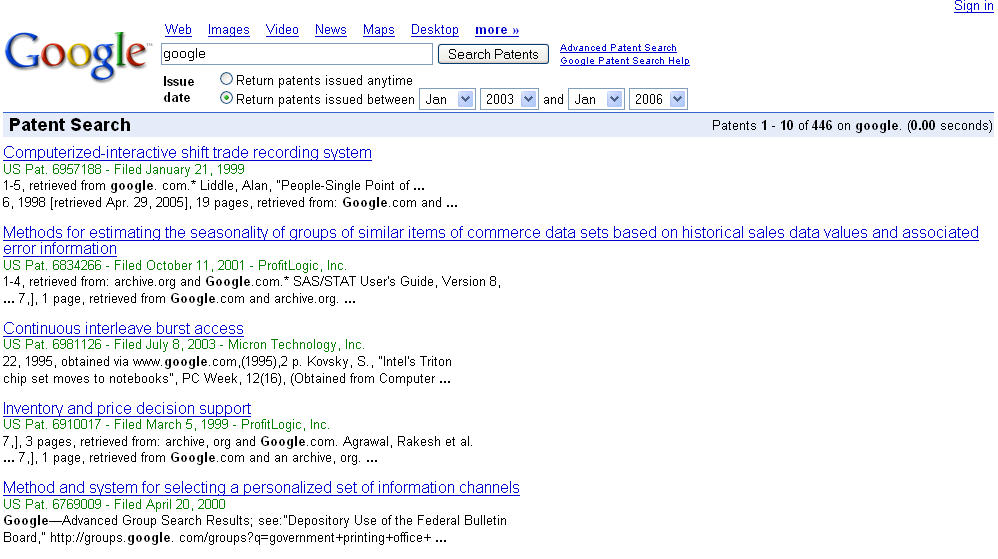
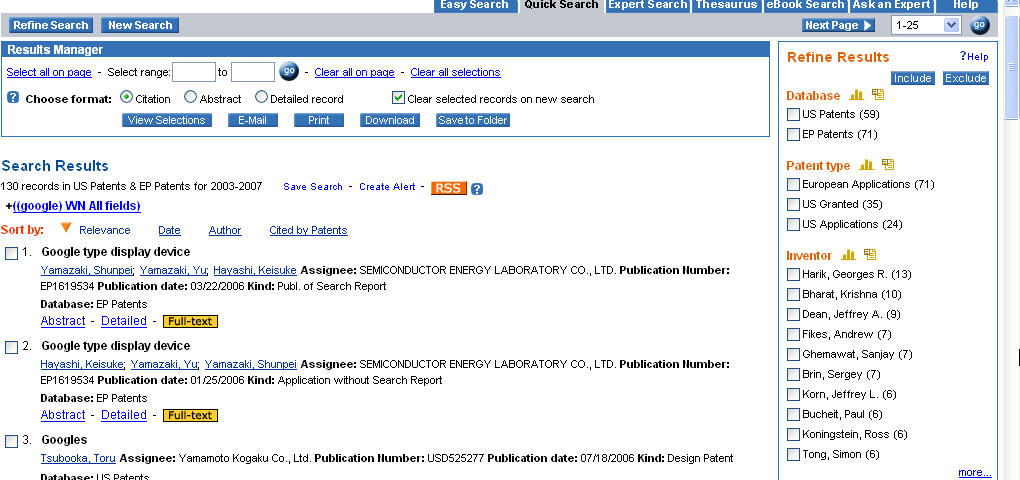
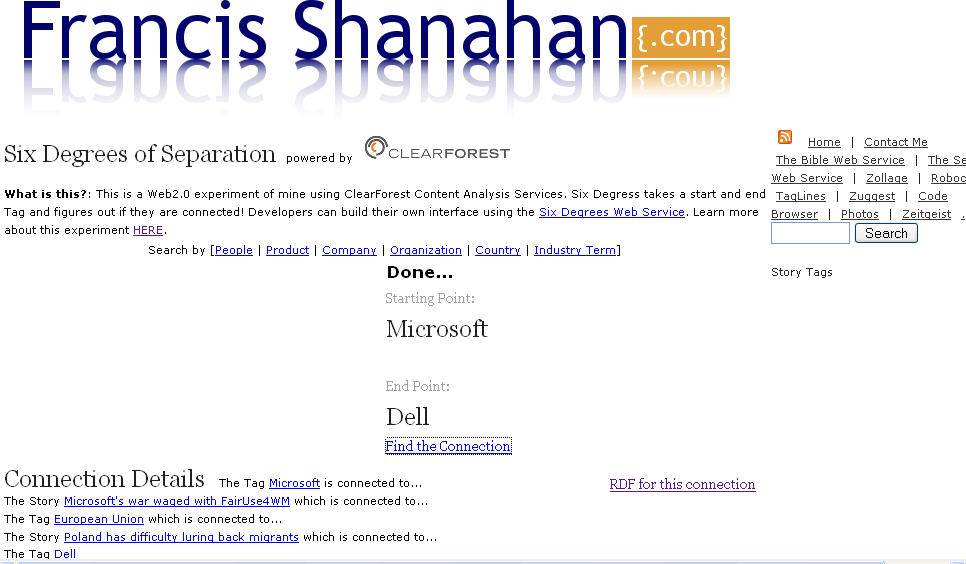
Since when bloggers can't post on old news that newspapers are reporting?
When I started this blog I never thought that I was supposed to "be able to break stories faster than mainstream journalists. " I am not keeping this blog to compete or break stories faster than mainstream journalists. I saw an article in a newspaper about a company that I liked what they were doing with faceted search and I posted. It's so simple and let's keep simplicity for blogging..... btw Steve Rubel, Techcrunch, Mashable has more insights and better coverage than my single line about Rawsugar.